The Newton-Muon Optimizer
Published:
Muon has a surprisingly simple update. Given a matrix gradient \(G\in\mathbb{R}^{m\times n}\), it applies the matrix sign operator to \(G\) to produce an update matrix \(Q\in\mathbb{R}^{m\times n}\):
\[Q\propto \operatorname{msgn}(G).\]Here \(\operatorname{msgn}(A)=UV^\top\) for a compact SVD \(A=USV^\top\). At first glance, this looks almost too simple. Why should replacing a gradient by its matrix sign be a good idea?
In this blog, we explain one way to see why Muon works: under a layer-wise quadratic model, Muon is almost Newton’s method. The only missing piece is the input data geometry. Newton-Muon puts that piece back. In formulas, Newton-Muon will replace \(\operatorname{msgn}(G)\) by \(\operatorname{msgn}\!\left(G(ZZ^\top)^{-1}\right)\), where \(Z\) stacks the layer inputs.
Local Second-Order Expansion
Let \(f\) be the loss function, \(W\in\mathbb{R}^{m\times n}\) be the weight matrix of a single layer, \(G=\nabla_{W} f(W)\in\mathbb{R}^{m\times n}\) be the gradient, and let \(Q\in\mathbb{R}^{m\times n}\) denote an update matrix. The second-order expansion is
\[f(W-Q)\approx f(W)-\operatorname{tr}(QG^\top)+\frac12\,\operatorname{vec}(Q)^\top\mathcal{H}_W\operatorname{vec}(Q), \tag{1}\label{eq:quadratic-model}\]where \(\mathcal{H}_{W}=\nabla^2_{\operatorname{vec}(W)}f(W)\in\mathbb{R}^{mn\times mn}\) is the parameter-space Hessian, and \(\operatorname{vec}(\cdot)\) flattens a matrix into a vector.
This is the natural place to start if we want to understand Newton-like behavior. The obstacle, of course, is that the Hessian \(\mathcal{H}_{W}\) is intractable. So the next step is to expose some structure.
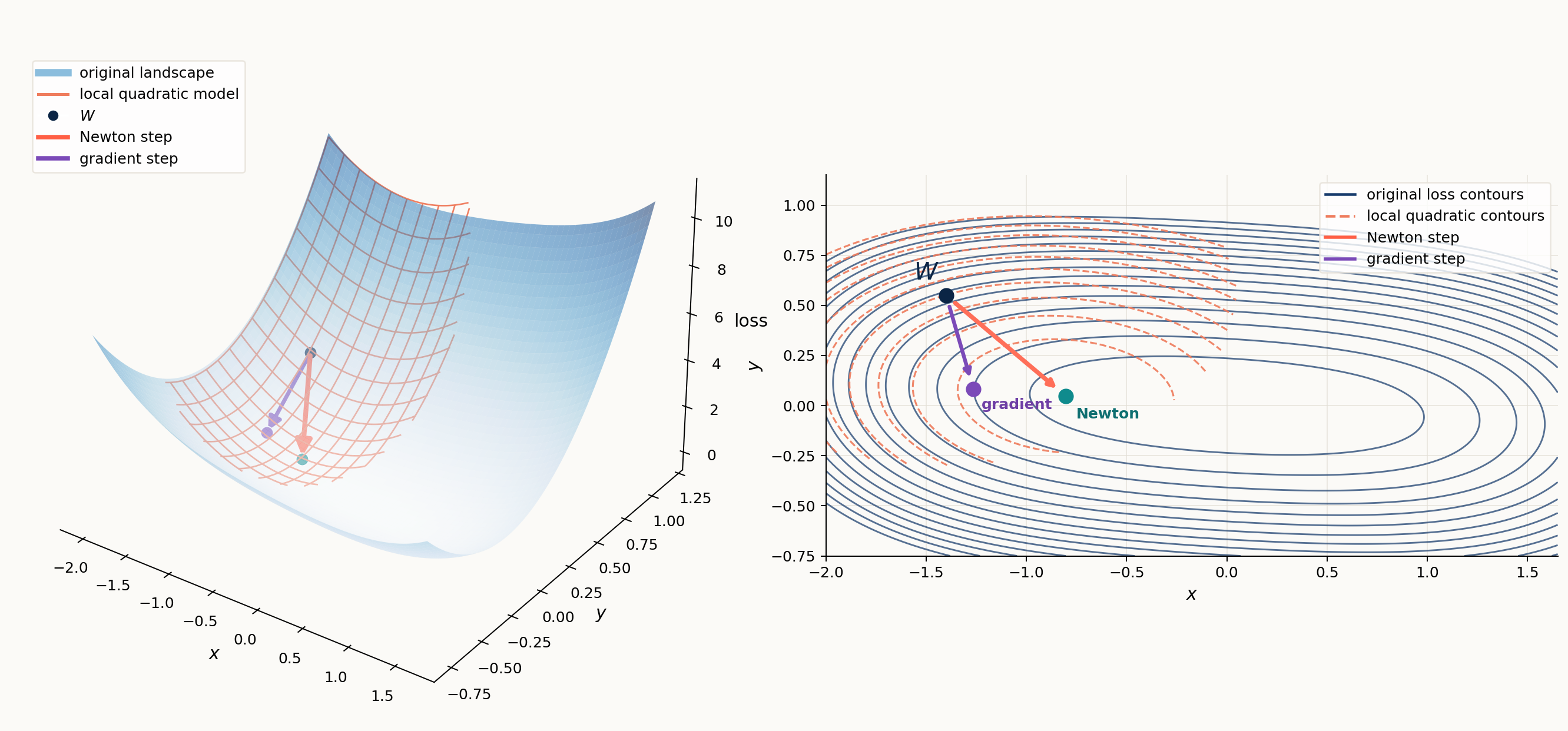
Kronecker-Factored Curvature
For one sample, let \(z_i\in\mathbb{R}^{n}\) be the input and let \(y_i=Wz_i\in\mathbb{R}^{m}\) be the output. Write the sample loss as \(\ell_i(W)=L_i(y_i)\), and assume the single-sample output curvature is \(H_i=\nabla_{y_i}^{2}L_i(y_i)\in\mathbb{R}^{m\times m}\).
Since \(y_i=Wz_i\), by the matrix derivative rule, this single-sample curvature \(H_i\) contributes the following term to \(\mathcal{H}_W\). Here \(I_m\in\mathbb{R}^{m\times m}\) is the identity matrix and \(\otimes\) denotes the Kronecker product:
\[\nabla_{\operatorname{vec}(W)}^2\ell_i(W) = (z_iz_i^\top)\otimes H_i \in\mathbb{R}^{mn\times mn}.\]Averaging these single-sample curvature contributions over \(N\) samples gives the empirical parameter-space Hessian \(\mathcal{H}_W\) (where we ignore token-coupled curvature in attention mechanisms):
\[\mathcal{H}_W = \frac1N\sum_{i=1}^{N}(z_iz_i^\top)\otimes H_i \in\mathbb{R}^{mn\times mn}.\]Now, we replace the sample-dependent \(H_i\) by a global average curvature \(H=N^{-1}\sum_{i=1}^{N}H_i\in\mathbb{R}^{m\times m}\) and decouple it from the input second moment. With \(Z=[z_1,\dots,z_N]\in\mathbb{R}^{n\times N}\),
\[\mathcal{H}_W \approx (ZZ^\top/N)\otimes H. \tag{2}\label{eq:kfac}\]This is the K-FAC-style approximation; see Optimizing Neural Networks with Kronecker-factored Approximate Curvature.
From Curvature to Displacement
Let \(W^{\star}\in\mathbb{R}^{m\times n}\) be a local minimizer near \(W\), so \(\nabla f(W^{\star})=0\). The integral Taylor expansion of the gradient along the segment from \(W^{\star}\) to \(W\) gives
\[\operatorname{vec}(G) = \operatorname{vec}(\nabla f(W)) = \left[ \int_{0}^{1} \nabla_{\operatorname{vec}(W)}^{2} f\!\left(W^{\star}+t(W-W^{\star})\right) \,\mathrm{d}t \right] \operatorname{vec}(W-W^{\star}).\]We replace this path-averaged Hessian by the fixed parameter-space Hessian \(\mathcal{H}_{W}\). This gives the local Newton relation
\[\operatorname{vec}(G)\approx \mathcal{H}_{W}\operatorname{vec}(W-W^{\star}). \tag{3}\label{eq:local-newton}\]Matrix-Sign Representation of the Newton Step
Here comes the magic part.
Under the assumptions in \(\eqref{eq:kfac}\) and \(\eqref{eq:local-newton}\), treated as exact, and assuming \(H\succ0\) and \(ZZ^\top\succ0\), the optimal solution \(Q^\star\) to the quadratic model \(\eqref{eq:quadratic-model}\) can be written directly as:
\[Q^\star = \Sigma_W^{1/2}\operatorname{msgn}\!\left(\Sigma_W^{1/2}G(ZZ^\top)^{-1}\right) \tag{4}\label{eq:exact-qstar}\]where \(\Sigma_W=(W-W^\star)(W-W^\star)^\top\). The proof is just algebra. We move it to the end of the blog.
Isotropic Displacement Approximation
The expression above still contains \(\Sigma_W\), which depends on the unknown displacement \(W-W^\star\). To turn the formula into a practical optimizer, adopt the isotropic displacement approximation
\[\Sigma_{W}\propto I_{m}.\]This proxy treats the unknown displacement directions as isotropic in aggregate.
Then \(\Sigma_{W}^{1/2}\propto I_{m}\), and the exact expression \(\eqref{eq:exact-qstar}\) reduces to
Newton-Muon
$$ Q^\star\propto \operatorname{msgn}\!\left(G(ZZ^\top)^{-1}\right). $$If the input second moment is also isotropic, \(ZZ^{\top}\propto I_{n}\), where \(I_n\in\mathbb{R}^{n\times n}\) is the identity matrix, then we recover standard Muon:
Muon
$$ Q^{\star}\propto \operatorname{msgn}(G). $$Thus standard Muon is the special case obtained by discarding the right preconditioner induced by the input activations.
A direct descent argument follows. Let \(G_{r}=G(ZZ^{\top})^{-1}\in\mathbb{R}^{m\times n}\) denote the right-preconditioned gradient. If \(G_{r}=USV^{\top}\) is a compact SVD with \(S\succeq 0\) diagonal, then \(Q=\operatorname{msgn}(G_{r})=UV^{\top}\) and
\[\operatorname{tr}(G^{\top}Q)=\operatorname{tr}(ZZ^{\top}VSV^{\top})\ge 0,\]since \(ZZ^{\top}\succeq 0\) and \(VSV^{\top}\succeq 0\). So, under \(ZZ^\top\succ0\), the Newton-Muon direction is a descent direction whenever \(G_r\neq0\).
Modded-NanoGPT Result
On Record #4 of the short-track Modded-NanoGPT reproduction, Newton-Muon reaches Muon’s final validation loss using 6% fewer optimization steps and approximately 4% less wall-clock time.
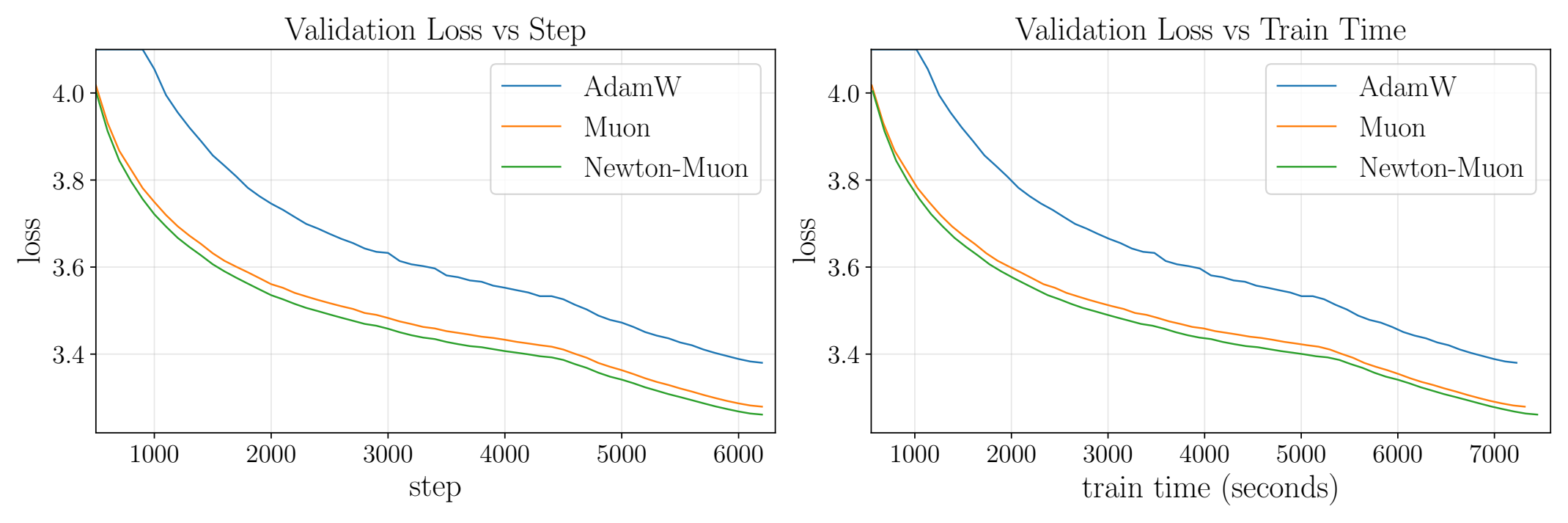
The gain is not a giant architectural change. It is a small optimizer-level correction. But that is exactly why the result is interesting: a simple input-covariance preconditioner gives Muon a cleaner Newton interpretation and a measurable practical improvement.
Proof of the Matrix-Sign Formula
Assume the approximations \(\eqref{eq:kfac}\) and \(\eqref{eq:local-newton}\) hold exactly, and assume \(H\succ0\) and \(ZZ^\top\succ0\). The first-order condition for the quadratic model \(\eqref{eq:quadratic-model}\) gives
\[\mathcal{H}_W\operatorname{vec}(Q^\star)=\operatorname{vec}(G). \tag{5}\label{eq:proof-stationarity}\]Combining \(\eqref{eq:proof-stationarity}\) with the exact version of \(\eqref{eq:local-newton}\) gives \(\operatorname{vec}(Q^\star) = \operatorname{vec}(W-W^\star)\), so
\[Q^{\star}=W-W^{\star}. \tag{6}\label{eq:proof-newton-direction}\]Next, use \(\eqref{eq:kfac}\) and \(\eqref{eq:proof-newton-direction}\) in \(\eqref{eq:proof-stationarity}\), together with \(\operatorname{vec}(AXB)=(B^\top\otimes A)\operatorname{vec}(X)\):
\[\operatorname{vec}(G) = \left((ZZ^\top/N)\otimes H\right)\operatorname{vec}(W-W^\star) = \operatorname{vec}\!\left(H(W-W^\star)ZZ^\top/N\right).\]Thus
\[G(ZZ^\top)^{-1}=H(W-W^\star)/N. \tag{7}\label{eq:preconditioned-gradient-proof}\]Take the compact SVD \(W-W^{\star}=U_QS_QV_Q^{\top}\). Then \(\Sigma_{W}^{1/2}=U_QS_QU_Q^{\top}\). Using \(\eqref{eq:preconditioned-gradient-proof}\),
\[\Sigma_W^{1/2}G(ZZ^\top)^{-1} = \frac1N\,U_QS_Q(U_Q^\top H U_Q)S_QV_Q^\top.\]Since \(H\succ0\) and \(S_Q\) has positive diagonal entries, the middle factor \(N^{-1}S_Q(U_Q^\top H U_Q)S_Q\) is symmetric positive definite. Therefore
\[\operatorname{msgn}\!\left(\Sigma_W^{1/2}G(ZZ^\top)^{-1}\right) = U_QV_Q^\top.\]Finally, because \(U_Q^\top U_Q=I_r\),
\[\Sigma_W^{1/2}\operatorname{msgn}\!\left(\Sigma_W^{1/2}G(ZZ^\top)^{-1}\right) = \Sigma_W^{1/2}U_QV_Q^\top = U_QS_QU_Q^\top U_QV_Q^\top = U_QS_QV_Q^\top = W-W^\star.\]Combining the last display with \(\eqref{eq:proof-newton-direction}\) proves \(\eqref{eq:exact-qstar}\):
\[Q^\star = \Sigma_W^{1/2}\operatorname{msgn}\!\left(\Sigma_W^{1/2}G(ZZ^\top)^{-1}\right).\]This proves the matrix-sign representation of the Newton step.
Citation
@article{du2026newton,
title={The {N}ewton-{M}uon optimizer},
author={Du, Zhehang and Su, Weijie},
journal={arXiv preprint arXiv:2604.01472},
year={2026}
}